System Health Leads the Industry in Accuracy on MedQA
David Kang, Eugénie Dulout
6.17.2026
A recent paper in Nature Medicine by Vishwanath et al. from NYU Langone Health evaluates two clinical AI tools, OpenEvidence and UpToDate Expert AI, built on large language models (LLMs) against three frontier LLMs. The authors conclude that both clinical AI tools underperform the frontier LLMs.
MedQA, a widely-used benchmarking dataset with a multiple-choice format, is used as one of the evaluations in the study. It provides a broad question base sourced from USMLE and other medical licensing exams.
We evaluated our clinical evidence synthesis API, Synthesize, on 500 MedQA-USMLE-style questions sampled from the publicly available MedQA-USMLE-4-options dataset on Hugging Face, using the same random seed reported in the study (seed = 62). We generated multiple-choice selections and the rationale and citations that are produced for every response (data available here). We then followed the study’s MedQA scoring approach, using GPT-4.1 (gpt-4.1-2025-04-14) to extract the final answer choice from each response and compare it against the reference key, with regex-based extraction run in parallel as a consistency check.
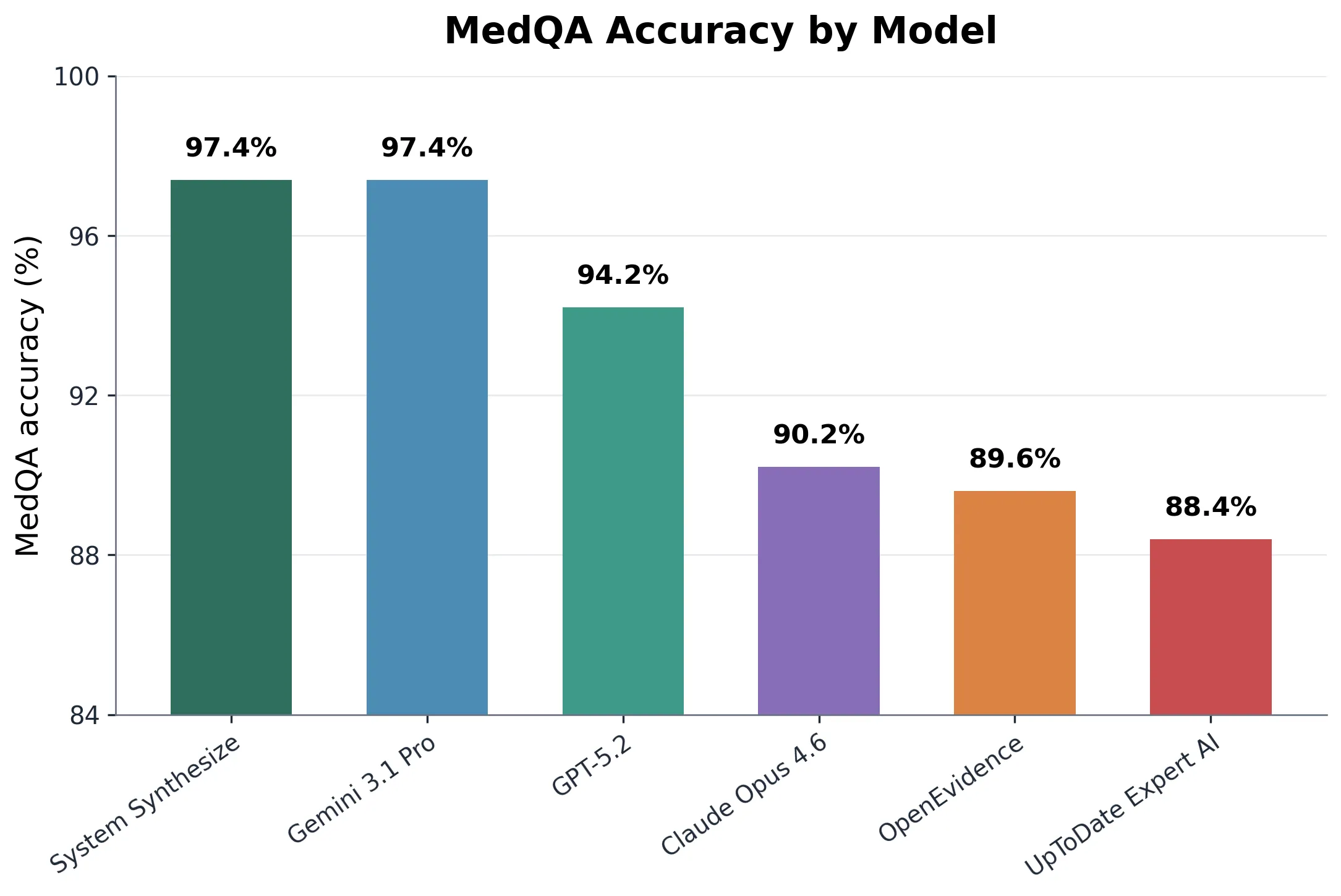
System Health’s Synthesize API achieved 97.4% accuracy (487/500), outperforming OpenAI’s GPT-5.2, Anthropic’s Claude Opus 4.6, OpenEvidence, and UpToDate Expert AI and tying with Google’s Gemini 3.1 Pro.
We previously reported that our Synthesize API achieved perfect scores on the USMLE. Combined, these results demonstrate the power and potential of the System Clinical Graph and System’s patented information extraction and knowledge base construction methodologies to transform clinical decision support.
At the same time, we believe that further rigorous and diverse testing of clinical AIs is necessary to ensure their safety and accuracy, and we remain committed to this ongoing research.
System Health Leads the Industry in Accuracy on MedQA
David Kang, Eugénie Dulout
June 17, 2026
A recent paper in Nature Medicine by Vishwanath et al. from NYU Langone Health evaluates two clinical AI tools, OpenEvidence and UpToDate Expert AI, built on large language models (LLMs) against three frontier LLMs. The authors conclude that both clinical AI tools underperform the frontier LLMs.
MedQA, a widely-used benchmarking dataset with a multiple-choice format, is used as one of the evaluations in the study. It provides a broad question base sourced from USMLE and other medical licensing exams.
We evaluated our clinical evidence synthesis API, Synthesize, on 500 MedQA-USMLE-style questions sampled from the publicly available MedQA-USMLE-4-options dataset on Hugging Face, using the same random seed reported in the study (seed = 62). We generated multiple-choice selections and the rationale and citations that are produced for every response (data available here). We then followed the study’s MedQA scoring approach, using GPT-4.1 (gpt-4.1-2025-04-14) to extract the final answer choice from each response and compare it against the reference key, with regex-based extraction run in parallel as a consistency check.
System Health’s Synthesize API achieved 97.4% accuracy (487/500), outperforming OpenAI’s GPT-5.2, Anthropic’s Claude Opus 4.6, OpenEvidence, and UpToDate Expert AI and tying with Google’s Gemini 3.1 Pro.
We previously reported that our Synthesize API achieved perfect scores on the USMLE. Combined, these results demonstrate the power and potential of the System Clinical Graph and System’s patented information extraction and knowledge base construction methodologies to transform clinical decision support.
At the same time, we believe that further rigorous and diverse testing of clinical AIs is necessary to ensure their safety and accuracy, and we remain committed to this ongoing research.

.webp)
.webp)